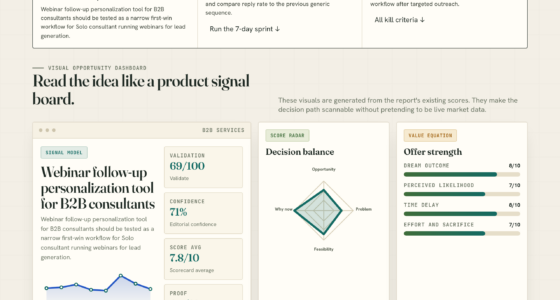
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
In 2026, the AI industry faces a turning point as publicly available data becomes exhausted. Companies now compete for rare, verified data behind paywalls and in specialized domains, transforming data into a protected, high-value asset.
In 2026, the AI industry has reached a critical point where publicly available data has become largely exhausted, prompting a shift toward fencing and licensing of rare, verified data sources. This change underscores how data ownership has become a key competitive advantage, replacing the era when models could be trained on freely scraped web content.
Recent industry estimates suggest that the public internet contains approximately 300 trillion tokens of high-quality text, a resource already nearing full utilization for training large language models. For more insights, see The Frameworks Can’t See the Thing That Matters. As synthetic data and more efficient algorithms extend dataset utility, the real scarcity now lies in verified, human-made data. Major legal developments, such as Anthropic’s $1.5 billion settlement over copyright infringement, mark the end of free scraping and signal the emergence of a market-based licensing regime for training data.
This legal shift favors established players with deep pockets, creating a barrier for startups and smaller labs. Learn more about the evolving AI landscape in The Frameworks Can’t See the Thing That Matters. Meanwhile, the industry has shifted focus from broad web crawling to acquiring specialized, high-value data from paywalled sources, enterprises, and expert domains. This trend is discussed in The Frameworks Can’t See the Thing That Matters. The move has also intensified competition for rare data generated by experts in fields like law, medicine, and military operations, where data is authored rather than labeled.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Ownership Is Now a Critical Industry Asset
This development matters because access to scarce, verified data now determines competitive advantage in AI. The era of free web scraping is ending, replaced by a landscape where data fencing and licensing create high barriers to entry. This shift benefits large incumbents who can afford licensing fees and specialized data collection but leaves smaller players at a disadvantage, potentially consolidating industry power and slowing innovation from startups.
![Express Schedule Free Employee Scheduling Software [PC/Mac Download]](https://m.media-amazon.com/images/I/41yvuCFIVfS._SL500_.jpg)
Express Schedule Free Employee Scheduling Software [PC/Mac Download]
Simple shift planning via an easy drag & drop interface
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Industry Shifts Reshape Data Acquisition Strategies
Historically, AI models relied heavily on freely accessible web data, with companies scraping vast amounts of content. However, legal actions such as Anthropic’s $1.5 billion settlement over copyright infringement have established that scraping copyrighted material without licensing is no longer viable. This has prompted a move toward market-based licensing regimes, with publishers and content creators demanding compensation for their data. As a result, data has transformed from a free input to a valuable, protected asset, concentrating control among a few large firms.
Simultaneously, the industry has shifted from simple data labeling to sourcing expert-authored data, which is expensive but critical for advanced reasoning and domain-specific AI capabilities. This change has created a new battleground for acquiring high-quality, verified data, often behind paywalls or within enterprise environments.
“The $1.5 billion settlement ratifies that copyrighted material cannot be used freely for training without licensing, marking a fundamental change in industry practices.”
— Legal expert familiar with Anthropic settlement

AIGP Certification Mastery Guide: Complete AI Governance Professional Exam Prep System with Brain Science-Based Learning, Expert Tricks, 1200 Practice Q&As + Explanations (12 Full-Length Tests)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Impact on Innovation and Startup Access
It remains uncertain how the increased costs and legal barriers will affect innovation, especially among startups and smaller labs. While large companies can afford licensing fees, the barrier to entry may slow the development of new models and limit diversity in AI research. The long-term effects of this data fencing on industry competition and innovation are still unfolding.

Spotlight-Mode Synthetic Aperture Radar: A Signal Processing Approach: A Signal Processing Approach
Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Industry Adaptation and New Data Market Dynamics
Moving forward, expect continued legal clarifications and potentially new regulations governing data licensing. Companies will likely invest more in acquiring high-value, verified data and developing synthetic alternatives with caution. The industry may also see the emergence of specialized data marketplaces and partnerships with content creators, shaping a new ecosystem where data ownership and licensing are central to AI development.

A&D EK1200i Legal for Trade Gold Scale – Certified Precision for Professional Jewelry Weighing
Legal for Trade Certification: Certified to meet legal standards for trade, ensuring accuracy and compliance in commercial transactions…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is publicly available data running out for AI training?
Estimates indicate that the public internet contains nearly 300 trillion tokens of high-quality text, which is approaching full utilization for training large models. Legal actions and the exhaustion of free data sources have accelerated this scarcity.
How has the legal landscape changed for data used in AI training?
Legal settlements like Anthropic’s $1.5 billion deal have established that scraping copyrighted material without licensing is not fair use, leading to the end of free scraping and the rise of licensing regimes for training data.
What types of data are now considered most valuable?
High-value data now includes verified, human-authored datasets from experts, paywalled sources, and specialized domains such as medicine, law, and military operations, which are difficult to replicate synthetically.
Will smaller startups be able to compete in this new data environment?
It is uncertain. The high costs of licensing and acquiring rare data could favor large incumbents, potentially limiting opportunities for smaller players and reducing industry diversity.
Source: ThorstenMeyerAI.com